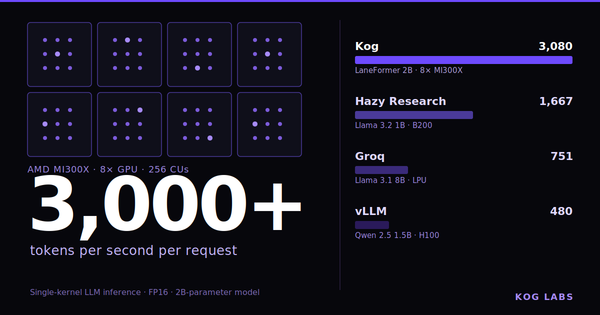
Real-time LLM Inference on Standard Datacenter GPUs (3,000 tokens/s per request)
Today, Kog AI launches a tech preview of the Kog Inference Engine (KIE): 3,000 output tokens/s per request on 8× AMD MI300X GPUs and 2,100 on 8× NVIDIA H200 (FP16, no speculative decoding). This preview runs a 2B model, with support for large third-party MoE models coming next at similar speeds.
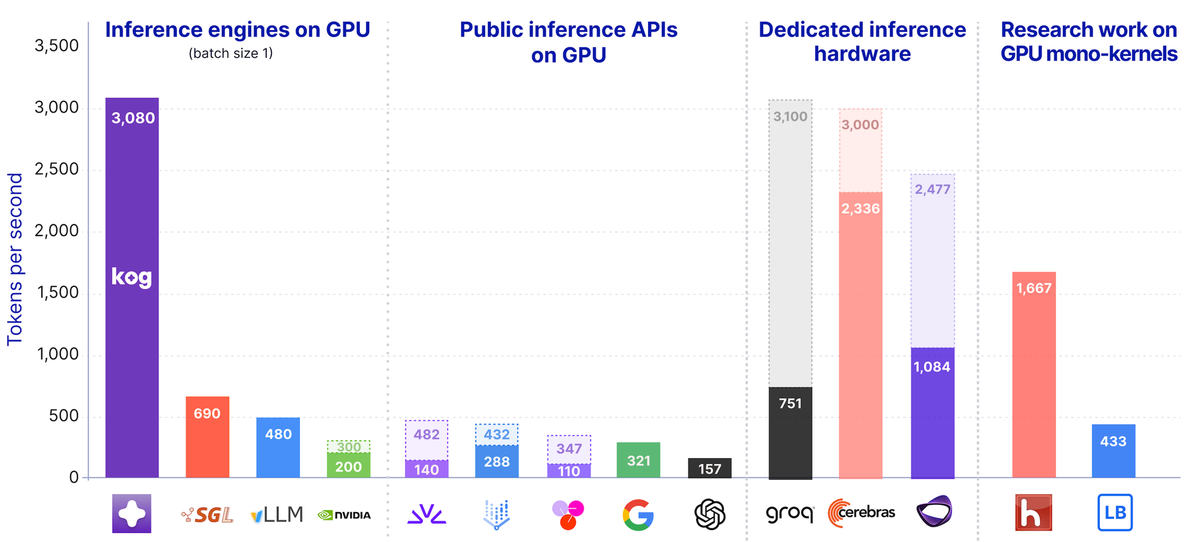
TL;DR: we show that AI inference on GPUs can be super-fast, reaching the speed regime of dedicated inference hardware cards when optimizing the whole software stack with architecture/engine/kernel co-design. Test the speed in our live coding playground: playground.kog.ai.
This post explains why optimizing for single-request LLM decoding speed is important for AI agents; why it's primarily a memory-bandwidth maximization problem, not a FLOPS one; why standard datacenter GPU hardware has a much higher decoding-speed ceiling than current inference stacks expose due to software bottlenecks; and how that ceiling can be reached (even on large MoE models) by co-designing the model architecture, runtime, and low-level GPU code as a single latency-optimized pipeline.
Our public tech preview is about proving that extremely fast single-request decoding is possible on the standard datacenter GPUs enterprises already own — including AI labs and sovereign-AI buyers. The limiting factor has been that existing inference software stacks are not optimized for this type of workload. Opening the GPU path could deliver that speed without the lock-in of proprietary silicon.
You can test the speed of our 2B coding model today. It's small and not a frontier model (we've been focused on speed rather than scale), though still quite capable when fine-tuned for specific software engineering tasks.
What autonomous agents change: single-request decode speed is now the metric that matters
Inference benchmarks typically conflate three quantities. Aggregate throughput (total tokens generated per second across all users) measures server utilization and rewards large batches. Time to first token measures prefill latency. Decode speed per request measures token generation speed and defines how long one user waits before receiving the full response. That last one governs every long serial interaction, and it's what AI agents are bottlenecked on.
Agentic software engineering is a sequential loop: inspect, plan, edit, test, revise. Each step depends on the previous one. Tool time sometimes dominates, as tests have to run and web pages have to load, but the generation-heavy steps (planning, code writing, trace analysis, debugging, refactoring) set the loop rate. And reasoning tokens compound on top.
The numbers translate directly into product and user experience. If an agent needs to generate 50,000 tokens in a workflow, 100 tokens/s is roughly eight minutes; 3,000 tokens/s is under twenty seconds. The difference changes the product that can be built.
As agents become more autonomous, the productivity frontier shifts from intelligence alone to intelligence × iteration speed. The best agents will generate more useful tokens, reason more, and perform more tool calls, tests, and revisions inside the same wall-clock budget.
This is why Kog optimizes single-request latency first, and why this preview runs at batch size 1. Large batches do matter and we will support them in production, but they answer a different question.
But what is limiting decode speed on GPUs?
Memory bandwidth is the primary bottleneck for fast token generation (and GPU nodes have plenty)
At batch size 1, autoregressive decoding is dominated by matrix-vector work. For each generated token, all the active weights of the model must move through the memory hierarchy inside the GPU, from HBM to compute processors. Thus, a first-order bound is:
tokens/s ≤ effective_memory_bandwidth
/ (β × active_weight_bytes + KV cache)
where β can be greater than one when tiles are reloaded or cache reuse is imperfect.
The key fact is that low-batch decode has very low arithmetic intensity. In FP16, a model weight occupies two bytes and contributes roughly one multiply-add (two FLOPs) which is about 1 FLOP/byte. FP8 raises it to ~2 FLOPs/byte; FP4 to ~4. However, modern AI GPUs expose hundreds of peak FLOPs per byte of HBM bandwidth. NVIDIA's H200, for example, claims a peak balance of roughly 400 FLOPs/byte. Thus, token generation speed is capped by memory bandwidth before being limited by FLOPS.
This is why Memory Bandwidth Utilization (MBU) is the central metric for single-request speed, not Model FLOP Utilization (MFU). MFU can still be improved by batching several requests together, which can however increase the latency experienced by each user as more KV cache data needs to be streamed inside the GPU.
For batch-size-1 decode, more memory bandwidth equals more tokens generated per second. The good news is that memory bandwidth of GPUs is already very high. An 8× NVIDIA H200 node exposes roughly 30.7 TB/s of effective aggregate memory bandwidth (taking 80% of the 4.8 TB/s theoretical per GPU as a realistic ceiling). An 8× AMD MI300X node reaches about 33.6 TB/s in practice (assuming 4.2 TB/s achievable per GPU).
Let's take a 2B-parameter dense model in FP16 as an example. It has roughly 4 GB of active weights, so if weights alone could be streamed perfectly (ignoring KV cache traffic and potential β reloads), the speed-of-light upper bounds would be:
- 8× H200: 30.7 TB/s ÷ 4 GB ≈ 7,700 tokens/s
- 8× MI300X: 33.6 TB/s ÷ 4 GB ≈ 8,400 tokens/s
Let's consider a few more examples: at batch size 1, the same speed results apply to a MoE with 4B active parameters in FP8; and a 32B-active-parameter MoE in FP4 would be bounded at ~2,000 tokens/s.
In a latency-first inference stack, a valid strategy is thus to parallelize inference on a full server node providing eight GPUs worth of HBM bandwidth.
It should also be noted that the next GPU generations (Rubin and MI450) coming in H2 2026 will provide about 4x higher memory bandwidth, thus allowing to reach the same speed for 4x bigger models, or with 4x fewer GPUs (potentially one or two instead of a full node). This will also help support bigger batch sizes at the same speed. At the end of this post, we'll dig a bit more on this topic to show that a decoding speed of thousands of tokens per second should be achievable on datacenter GPUs for current large state-of-the-art MoE models.
There is a catch, though. These bounds do not take into account non-GEMM operations stalls, intra-GPU synchronization, inter-GPU communication, instruction overhead, and so on. The key question is how continuously the system can stream the active model parameters through HBM and cache without interruptions. It turns out that making an 8-GPU server behave like a single continuous memory-streaming machine is, indeed, a hard problem.
Where standard inference stacks lose precious microseconds
At 3,000 tokens/s, the per-token budget is roughly 333 microseconds, including all layers, LM head and sampling. On a 25-layer model, spending just an extra 1 microsecond per layer consumes 7.5% of the time budget!
The usual abstraction stack — model graph logic written in a high-level language or framework like PyTorch or Triton, lowered into many kernels, scheduled by a CPU runtime, synchronized at kernel boundaries, and mediated by framework-level communication libraries — is flexible, facilitates maintainability and integration, and is great for general-purpose serving, including maximizing aggregated throughput at high batch sizes. This is the approach usually taken for models running on inference engines like vLLM, SGLang, and TensorRT-LLM. It is, however, poorly matched to a 333-microsecond token budget.
A simple launch-overhead calculation shows the problem. If a kernel launch and cleanup costs about 4.5 µs (as per our measurements on AMD MI300X), ten kernels per Transformer layer over twenty-five layers create 1,125 µs of overhead per token before any useful work, thus capping the achievable speed at ~890 tokens/s. Even just five aggressively fused kernels per layer still produce ~563 µs of overhead, capping speed around 1,780 tokens/s. And this is before taking into account the other sources of overhead, which compound on top of this.
Turning theoretical HBM bandwidth into useful model bandwidth is thus a matter of systematically identifying and killing the sources of microsecond loss:
| Standard inference stacks | Microsecond losses | Kog implementation |
|---|---|---|
| Kernel boundaries | Launch, cleanup, cache write-back, scheduler round-trips add overhead and break memory streaming. | Persistent monokernel: one GPU-resident program for the whole decode path. |
| CPU scheduling and sampling | Host-side logic introduces costly GPU-CPU communication and execution delays. | Full GPU-resident logic including LM-head sampling on the critical execution path. Optional zero-overhead asynchronous CPU logic for output streaming and EOS detection. |
| Grid synchronization | Matmul, attention, normalization, sampling, and routing all require GPU-wide synchronization and communication, at a cost of several microseconds per operation. | Optimized topology-aware intra-GPU grid sync and AllGather/AllReduce primitives; ~600 ns barrier on MI300X for small payloads. |
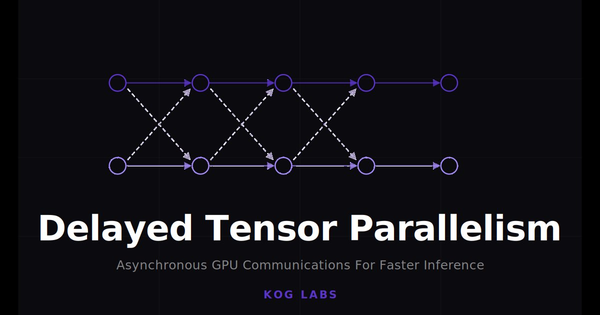
| Inter-GPU collectives | Tensor parallelism inserts two or three AllReduce operations in every layer's critical path. | Optimized KCCL communication primitives with AllReduce latency under 3 µs; Delayed Tensor Parallelism (DTP) communication in Kog's Laneformer model architecture. |
| Unified memory topology | Unified memory is actually not physically uniform: cache, HBM, IOD chiplets, and XCD placement all affect latency. | Topology-aware memory accesses with IOD-aware buffer placement, polling, and synchronization. |
| Weight reloads | Imperfect cache management and tile reuse during MatMuls raise β. | Cache- and register-aware kernel with memory layout optimized for low batch sizes. |
| Non-GEMM work | Computations of softmax, norms, routing, sampling, etc. pause memory streaming. | Monokernel with fused prefetch overlapping across computational sections. |
In a nutshell, standard inference stacks waste microseconds everywhere. That is where the available HBM bandwidth disappears.
The Kog stack co-designs the engine, the GPU code, and the model architecture to get these microseconds back
Inference systems are layered: a model on top of a runtime on top of GPU kernels. The model architecture constrains the communication schedule and the structure of the computational graph; the runtime controls scheduling and memory streaming; the GPU code decides whether synchronization, cache management, and topology are managed in a way that fits inside the budget. In existing inference engines, these layers are mostly tuned in isolation.
Kog recognizes the inter-dependencies of these three layers to their full extent, and co-designs them for maximum speed in the Kog Inference Engine.
That's why our critical decoding path does not rely on third-party frameworks, libraries, and abstractions (like PyTorch, Triton, CUTLASS, NCCL, ROCm CK, AITER, or RCCL). These are very valuable general-purpose tools, but our speed objective is narrower: batch-size-1 (or low batch size), full-node, low and medium active-parameter counts, with a budget of only a few hundred microseconds per token. The hot path is implemented in low-level, hand-crafted GPU code (CUDA with PTX inline assembly on NVIDIA, HIP with CDNA ISA inline assembly on AMD) and uses our own KCCL communication functions for collectives.
Here is a summary of some of our key innovations:
- Monokernel runtime and optimized GPU code. Our token generation runs as one persistent GPU program, instead of a sequence of per-operation kernels. It decodes the whole sequence in one pass without interruption. This monokernel removes all kernel boundaries, eliminates host-side scheduling and CPU-side token sampling from the critical path, and lets us control synchronization, communication, prefetch, and execution order and scheduling much more tightly than a conventional multi-kernel runtime. This approach is much harder to implement than ordinary fusion, because the same static GPU program must cover MatMul, attention, normalization, routing, sampling, and communication, which have each different computational shapes, buffer and register allocation needs, and synchronization. However, once implemented successfully, useful memory streaming is no longer repeatedly stopped by kernel boundaries. Deep dive in the Kog monokernel blog post for more details on our low-level GPU engineering optimizations.
- KCCL inter-GPU communications. A single request can use a full 8-GPU node only if the model is parallelized across GPUs. Standard tensor parallelism requires two (or three for a MoE model) all-reduce synchronizations in every layer; with enough layers, it's critical to avoid spending too many microseconds per collective. KCCL is Kog's custom collective-communication layer for this regime. Its objective is not peak aggregate bandwidth but predictable microsecond-scale latency that can be integrated into the monokernel schedule, keeping it under 3 µs where vendor libraries would spend ~8 µs. The code itself is tuned at the assembly level for each target GPU architecture, communication link characteristics, and buffer size.
- Laneformer model architecture. Kog's Laneformer model architecture is an innovative design around how multi-GPU nodes actually move data. Its core innovation, Delayed Tensor Parallelism (DTP, explained in detail in our blog post), changes the dependency structure of tensor-parallel decoding so that cross-device communication can be overlapped with useful computation rather than blocking the critical path. The model architecture itself is shaped by the latency structure of multi-GPU decoding.
Our chiplet-topology work on the AMD MI300X GPU is worth discussing, as an example of our hardware-aware software design approach:
- The problem: this GPU contains 8 XCDs (compute dies) placed on top of 4 I/O dies (IOD), and 8 HBM stacks behind a unified memory abstraction. 2 XCDs and 2 HBM stacks are attached to each IOD; communication with modules attached to a different IOD is subject to additional latency and a bandwidth bottleneck. The unified memory abstraction is useful for programming simplicity, but it hides non-uniform access paths: in our measurements, the physical route from an XCD to an HBM location changes latency enough to matter (up to 150 ns) and introduces skew between the compute units.
- Our solution: for grid synchronization and intra-GPU collectives, we measured barrier latency per XCD and mapped it to the chiplet topology, recovered the physical-memory-address-to-IOD mapping, and used this knowledge to replicate memory buffers on HBM stacks at controlled locations so each XCD polls memory from an HBM stack attached to its own I/O die. The resulting barrier is about 600 ns and stable across compute units.
The same engineering approach applies on NVIDIA Hopper: at this speed, each GPU package is a specific physical system, not an abstract accelerator.
By digging into the low-level hardware machinery, and adjusting our inference engine to it, we can find spare microseconds that are impossible to reach when using higher-level languages, libraries and frameworks.
What we're launching today
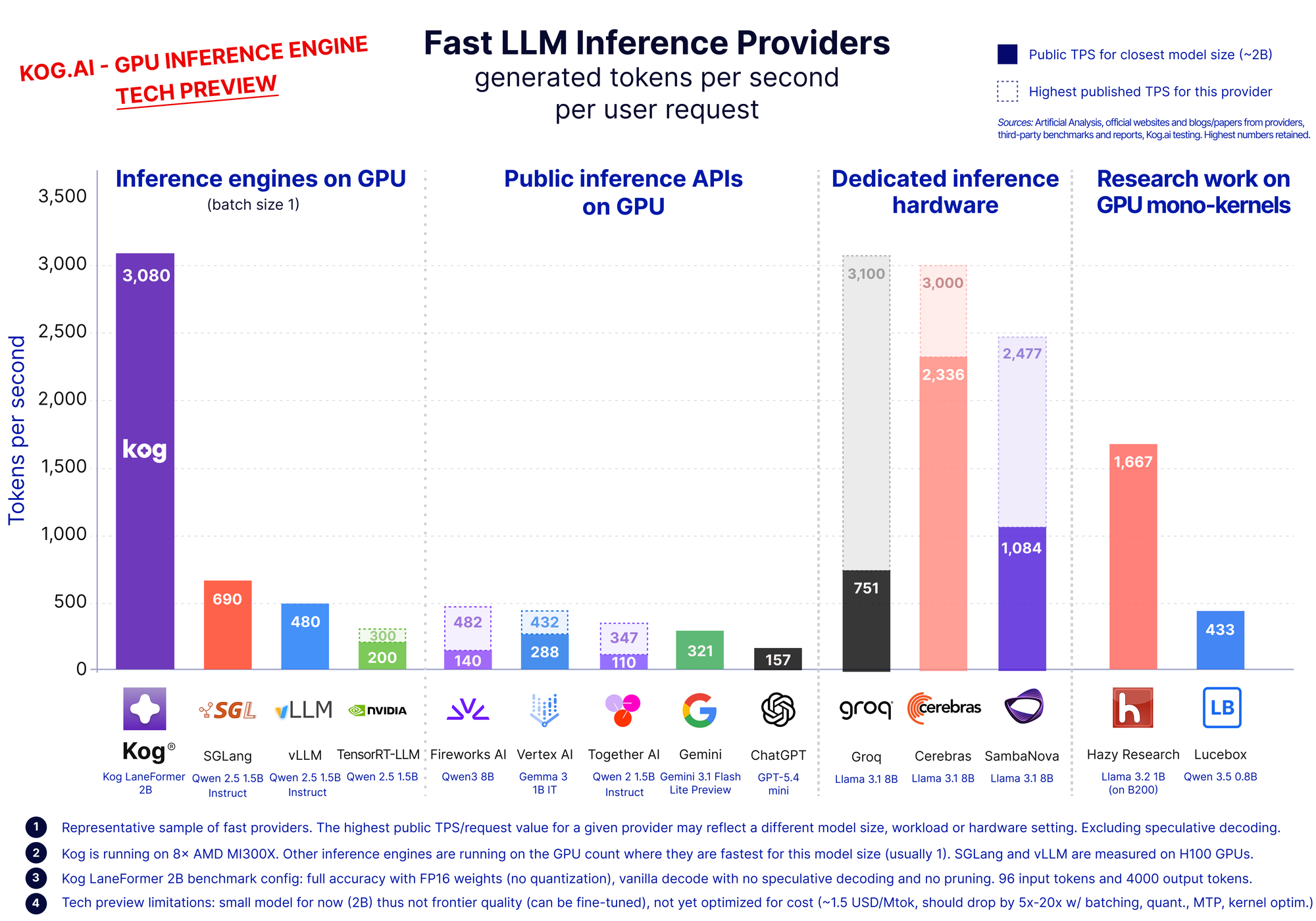
We open a tech preview of Kog Inference Engine's 3,000 tokens/s/req speed in a live playground running the Laneformer 2B model used in the above benchmark, with the same configuration on a single 8× MI300X node, at batch size 1.
Note that this preview is meant to make the speed observable, not to provide a frontier coding assistant. Our model scores 50% on the HumanEval coding benchmark, which is actually quite good for its size (Qwen2.5-Coder is at 43.9% for the 1.5B version and 52.4% for 3B), and shines when fine-tuned on specific SWE tasks. It uses vanilla autoregressive decoding on a 4096 sequence length (long context extension is under way to extend it to 128k). We pre-trained it on 6T tokens on the NVIDIA Nemotron v1 and v2 datasets, on a cluster of 256 H100 GPUs.
Importantly, we did not use other optimization tricks than the ones explained above: no quantization, no speculative decoding, no pruning, no early exit, no KV cache compression, etc. We do plan to implement this kind of low-hanging-fruit optimizations in our future roadmap, along with others, to facilitate support for larger models and batching at similar speeds (or just to increase the speed).
On a single 8x NVIDIA H200 node, our engine currently generates 2,100 tokens/s per request. We expect to match AMD GPU's speed in the near future.
Now, let's find out how we will scale this tech preview to accelerate the latest frontier AI models.
Scaling to large third-party MoE models
The next engineering step is to apply the same stack to larger third-party open-weight models (dense and MoE) with FP8/FP4 quantization and multi-token prediction techniques (like speculative decoding) when applicable.
Our scaling argument is built on active-parameter bytes moved in each forward pass, not total parameter count. For dense models, active parameters are essentially the full model. For MoEs, what matters is active parameters per generated token, which can be dramatically smaller than the total (numbers below are at batch size 1):
- Qwen3-Coder-Next: 80B total, 3B active.
- GPT-OSS-120B: 117B total, 5.1B active.
- DeepSeek-V4-Flash: 284B total, 13B active.
- Kimi-K2.6: 1.04T total, 32B active.
- Qwen3-Coder-480B-A35B: 480B total, 35B active.
- DeepSeek-V4-Pro: 1.6T total, 49B active.
The first-order bandwidth-only ceiling looks like this on a single 8-GPU node at 80% of theoretical aggregate bandwidth (numbers provided are output tokens per second):
| Model (active params, precision) | 8× H200 ~30.7 TB/s | 8× MI300X ~33.6 TB/s) | 8× B200 / MI355X ~51.2 TB/s | 8× MI450 ~125.4 TB/s | 8× Rubin ~140.8 TB/s |
|---|---|---|---|---|---|
| Qwen3-Coder-Next (3B, FP8) | ~10,200 | ~11,200 | ~17,100 | ~41,800 | ~46,900 |
| GPT-OSS-120B (5.1B, MXFP4/BF16) | ~6,150 | ~6,730 | ~10,300 | ~25,100 | ~28,200 |
| DeepSeek-V4-Flash (13B, MXFP4/FP8) | ~3,250 | ~3,560 | ~5,420 | ~13,300 | ~14,900 |
| Kimi-K2.6 (32B, INT4/BF16) | ~915 | ~1,000 | ~1,520 | ~3,730 | ~4,190 |
| Qwen3-Coder-480B-A35B (35B, FP8) | ~880 | ~960 | ~1,460 | ~3,580 | ~4,020 |
| DeepSeek-V4-Pro (49B, MXFP4/FP8) | ~860 | ~940 | ~1,430 | ~3,500 | ~3,940 |
These are upper bounds, not guaranteed achievable production speeds per se. As discussed in the previous sections, real speeds need to take into account per-layer slowdowns due to kernel launches, KV-cache traffic, β, non-GEMM work, routing, synchronizations, inter-GPU collectives, etc. This is where Kog's inference engine shines compared to traditional inference stacks.
There is an elephant standing in the room, though: for third-party models, we cannot utilize Delayed Tensor Parallelism, since the model architecture is fixed. We need to use standard Tensor Parallelism, and thus pay a latency cost for inter-GPU all-reduce communications 3 times per layer. Fortunately, the speed of our KCCL collectives, combined with our monokernel design, allows us to continue streaming model weights to compute units and memory caches while GPUs communicate. This does not fully remove the impact of such communications, but it reduces it significantly (remember that we are memory-bound, not compute-bound: so even if compute is paused for a little while, we will be able to catch up very easily — the real limiting factor is the size of shared memory buffers, register files, and caches that are used to fetch model weights into).
Now, to predict real numbers, let's rely on the fact that our tech preview achieves ~36% MBU. Assuming conservatively we would not improve this number (although we strongly believe that we will), and leaving potential quantization or multi-token prediction tricks out of the equation, it means that the numbers in the above table should be divided by ~2.8 to provide a reasonable estimate of the real output speed we should expect on MoE frontier models by using our current techniques (in tokens/s):
| Model (active params, precision) | 8× H200 ~30.7 TB/s | 8× MI300X ~33.6 TB/s | 8× MI355X / B200-class ~51.2 TB/s | 8× MI450 ~125.4 TB/s | 8× Rubin ~140.8 TB/s |
|---|---|---|---|---|---|
| Qwen3-Coder-Next (3B, FP8) | ~3,650 | ~4,000 | ~6,100 | ~14,900 | ~16,800 |
| GPT-OSS-120B (5.1B, MXFP4/BF16) | ~2,200 | ~2,400 | ~3,660 | ~8,970 | ~10,100 |
| DeepSeek-V4-Flash (13B, MXFP4/FP8) | ~1,160 | ~1,270 | ~1,940 | ~4,740 | ~5,320 |
| Kimi-K2.6 (32B, INT4/BF16) | ~325 | ~355 | ~545 | ~1,330 | ~1,500 |
| Qwen3-Coder-480B-A35B (35B, FP8) | ~315 | ~345 | ~520 | ~1,280 | ~1,440 |
| DeepSeek-V4-Pro (49B, MXFP4/FP8) | ~305 | ~335 | ~510 | ~1,250 | ~1,410 |
Of course these are ballpark estimates, and real numbers will differ. But the core idea holds.
As GPU HBM bandwidth grows and as the Kog stack — runtime, kernel, collectives, etc. — matures, we expect the speed of large frontier MoE models to move into the 1,000–5,000 tokens/s/request band on standard datacenter GPUs.
Conclusion
Dedicated inference hardware established single-request generation speed as a distinct infrastructure category that will become increasingly important with the rise of autonomous AI agents.
Until now, standard datacenter GPUs have not been able to compete in this category; not because of their hardware, but because of how the software inference stack has been built on top of them.
Our public preview demonstrates that a standard 8-GPU node can generate 3,000 output tokens per second per request on a 2B coding model at batch size 1, with no quantization or speculative decoding. We achieved that by treating the persistent runtime, low-level GPU code, and model architecture as one system.
The broader takeaway is that this is not limited to a small custom model. As available HBM bandwidth grows and the Kog stack matures, we expect the same kind of performance to carry over to the large open-weight MoEs at the frontier of AI agents today.
Explore these links to dig more
- Test our speed in the Kog Playground
- Blog post on Delayed Tensor Parallelism from our LLM architecture research team
- Technical deep dive from our GPU Engineering team on our monokernel runtime, including some of our low-level GPU optimizations for the AMD MI300X GPU.
- Design Partner Program for teams building coding agents, app-generation systems, or other agentic workflows where iteration speed is already a competitive bottleneck: we'll be happy to talk, please contact us through our website.
About Kog
Kog is a Paris-based AI infrastructure startup building a real-time inference engine for AI agents with innovative low-level GPU Engineering and LLM architecture research. Founded in 2023 by Gaël Delalleau — an École Polytechnique engineer whose career spans cybersecurity research and high-performance GPU work — Kog operates from Paris with a team of 11, including 10 engineers and researchers (5 PhDs).
Kog has raised $5M from Varsity VC and BPI France's Deep Tech Program, and was awarded the French Tech 2030 label in October 2025, a French government recognition granted to select national deep-tech companies contributing to strategic sectors.