Kog Reaches 3.5x Breakthrough Inference Speed on AMD Instinct MI300X GPUs
Kog Inference Engine reaches up to 3.5x faster token generation on AMD Instinct MI300X GPUs

TL;DR
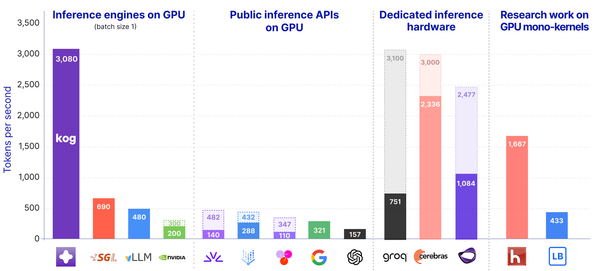
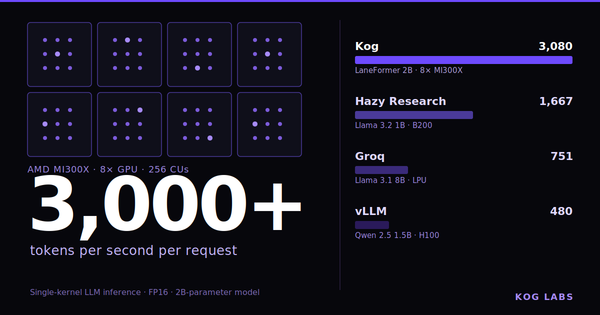
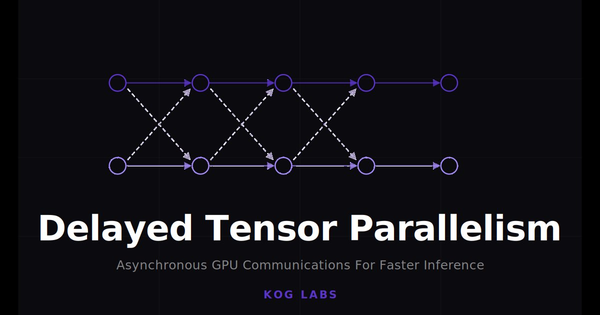
Kog Inference Engine hits up to 3.5× faster token generation than vLLM and TensorRT-LLM on AMD MI300X, across all tested model sizes (1B to 32B), with cross-GPU latency down to 4μs.
AMD covered Kog's inference results on MI300X in their engineering blog. Read the post on AMD's website ↗