Kog Laneformer 2B: The Latency-First Model Behind Kog Inference Engine

Today Kog is releasing the weights and model code of Laneformer 2B on Hugging Face Hub, the 2.3B-parameter instruction-tuned coding model designed for high-speed decoding.
Most LLM research optimizes for benchmark quality first, and inference metrics like speed are often treated as a serving problem that comes later: train the model, then quantize it, shard it, batch inputs, cache inputs, and write better kernels.
Kog took a different route and treated speed as our first objective. What changes when a model is designed from the ground up with decoding speed maximization in mind? Which architectural choices does that rule out, and which ones still preserve strong model performance?
This blog post is the story of how Kog trained Laneformer 2B from scratch into a capable coding model while respecting the hardware constraints required by our Kog Inference Engine and the budget constraints of a startup.
About Kog
Kog is a Paris-based AI infrastructure startup building a real-time inference engine for AI agents with innovative low-level GPU engineering and LLM architecture research.
For more background, see Kog's website and introductory blog post:
TL;DR
- Kog designed a lane-structured Transformer architecture for high-speed single-request decoding on our inference stack.
- Kog validated the custom architectural changes at small scale, then trained the final 2.3B model from scratch on ~4T pre-training tokens, continued on ~2T code/reasoning-heavy tokens, and instruction-tuned on ~210M tokens.
- Kog shows that, even with moderate resources, it is possible to build and deploy a custom small language model with competitive coding benchmark results in its size range.
- Laneformer 2B reaches 45.1% HumanEval+ and 51.6% MBPP+ in greedy decoding.
- Kog releases the weights, Hugging Face model code and documentation as kogai‑laneformer‑2b‑it ↗
- You can experience the accelerated version via our Kog Inference Engine on our playground ↗
The Laneformer 2B technical report is available on Hugging Face. Read the full report ↗
The idea
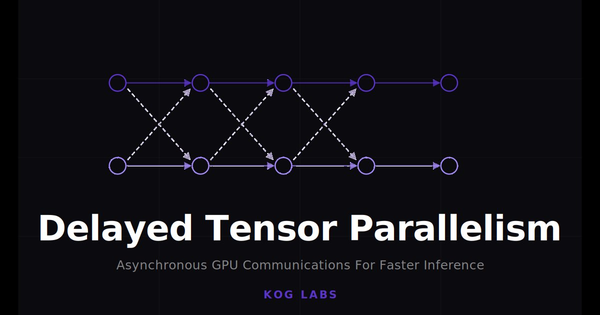
At low batch sizes, decode speed is not just a FLOPs problem. A lot of time goes into moving weights, synchronizing kernels, and paying communication costs layer after layer.
This overhead increases even more in multi-GPU setups, where inter-GPU communication is introduced. At the model architecture level, Tensor Parallelism (TP) is a well-known way to split work across GPUs, but each layer forces the devices to stop and exchange results before moving on to the next layer.
This led us to a simple question: can we hide those communication costs instead of paying them at every layer?
Naive attempts to solve this problem can introduce ad hoc architectural changes that hurt model quality, and make the method difficult to apply to an existing pre-trained architecture without leaving performance on the table.
Fast inference does not require training a new model from scratch and Kog's inference engine already achieves very high decoding speeds on standard pre-trained architectures through low-level GPU optimization. But to go further, the runtime can no longer be treated as a separate serving layer: the model architecture itself has to expose the right structure for the engine to exploit.
Those observations left us with a single conclusion: for the fastest single-request inference, architecture and runtime should be designed together. Laneformer is our first model trained from scratch to explore that co-design point.
As a small startup, we could not solve this by scaling indefinitely yet. The target had to be deliberately constrained: design and train a small-scale model with strong coding capabilities and extreme inference decoding speed.
The story
Hiding overhead
Tensor Parallelism (TP) is effective because it splits large matrix operations across GPUs and pays it with inter-GPU synchronization. At batch-size-one decoding, this cost is especially painful.
The obvious idea is to delay the communication introduced by TP. In practice, doing this naively leads to subpar model quality: once hidden states are no longer synchronized at the usual boundaries, model quality starts to drop off sharply and finding architectural ideas becomes necessary for training stability and maintaining model quality.
We spent this phase testing variants at small scale. Interestingly, many of our more complex ideas either degraded quality or made the implementation too brittle. The useful lesson was almost embarrassingly simple: try the obvious thing first! Understand why it fails and fix it with only the most minimal architectural change needed.
That path led to the mechanism we now call Delayed Tensor Parallelism (DTP). For the full mechanism, see our DTP deep dive.
Designing the architecture
Once DTP had a viable shape, the rest of the model design had to stay conservative. DTP was already changing one important assumption of a standard Tensor-Parallel Transformer, so we did not want to introduce unrelated architectural novelty at the same time.
There was also a speed budget. In the idealized limit where communication and other overheads are hidden, batch-size-one throughput becomes bounded by GPU memory bandwidth. Each generated token requires streaming model weights and the KV cache from GPU memory to compute units, so the maximum theoretical tokens per second depends strongly on how much data must be read per forward pass.
Since we were not targeting very long contexts in this release, the main practical question became: how large can the model be?
In theory, this question could be answered from hardware bandwidth alone. In practice, another constraint mattered just as much: what budget and compute could we actually sustain, and how long could we train?
The final size was therefore chosen at the intersection of three constraints:
- small enough to train from scratch with our resources,
- large enough to make coding benchmarks and post-training meaningful,
- support DTP and our inference engine to reach the highest speed possible.
The 2B scale ended up being perfect for us.
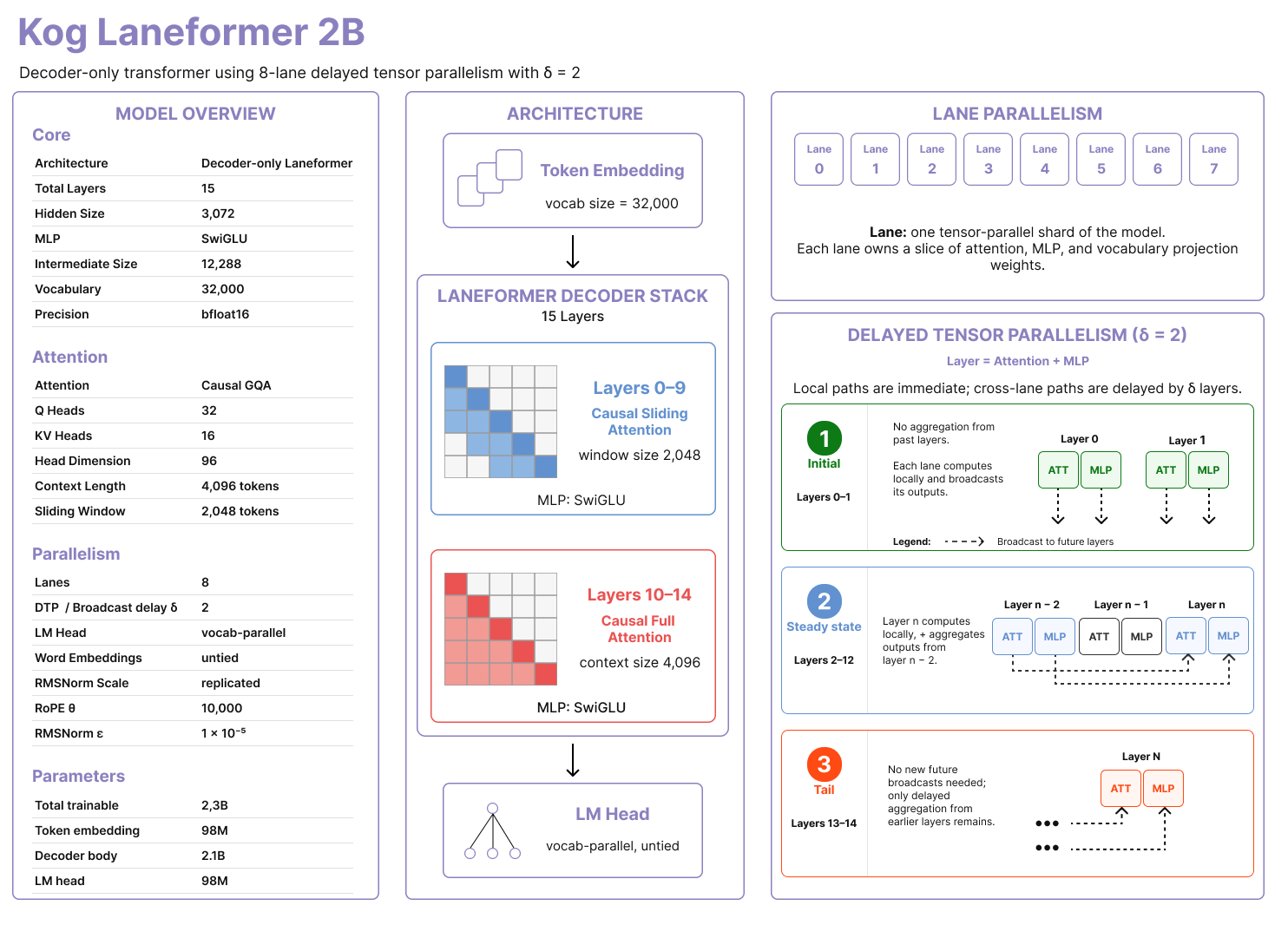
Below is our architecture card, showing how DTP and lanes fit into a mostly standard decoder Transformer.
Some notes:
- The strongest architectural change is the new 8-lane system to support DTP. To perfectly hide the TP communication overhead, we calibrated the delay to 2.
- We use causal Grouped-Query Attention (GQA) with 32 query heads and 16 key/value heads, allowing us to shard the heads evenly across our 8 lanes.
- We used Sliding Window Attention (SWA) for 10 of the 15 layers of the model to make sure streaming the KV cache would never introduce a non-negligible latency at our context size.
Pre-training and mid-training
Pre-training, even at the 2B scale, is a mountain to climb! Fortunately, today there are many useful resources, such as the Smol training playbook to help you get started.
So first, let's devise the data recipe!
Data mixtures and recipes
Our goal was to produce a capable coding model. Since we did not have access to proprietary data, we approached the problem under an open-source constraint.
Thanks to the current open ecosystem, and particularly NVIDIA's work on Nemotron, we were able to gather more than 20TB of high-quality filtered open-source data and avoid the long and costly data mixture search.
🤔 Remark
Getting 20TB of data from HF might sound simple, but working at this scale becomes a systems problem in its own right. Moving, filtering, validating, and reshuffling the data can take days, so small mistakes in the data pipeline can quickly become expensive.
Following the NVIDIA Nemotron paper, we used a multi-phase recipe as our starting point:
- start with a broad generalist data mixture,
- continue with a more focused data mixture,
- optionally end with a short final phase to improve specific capabilities.
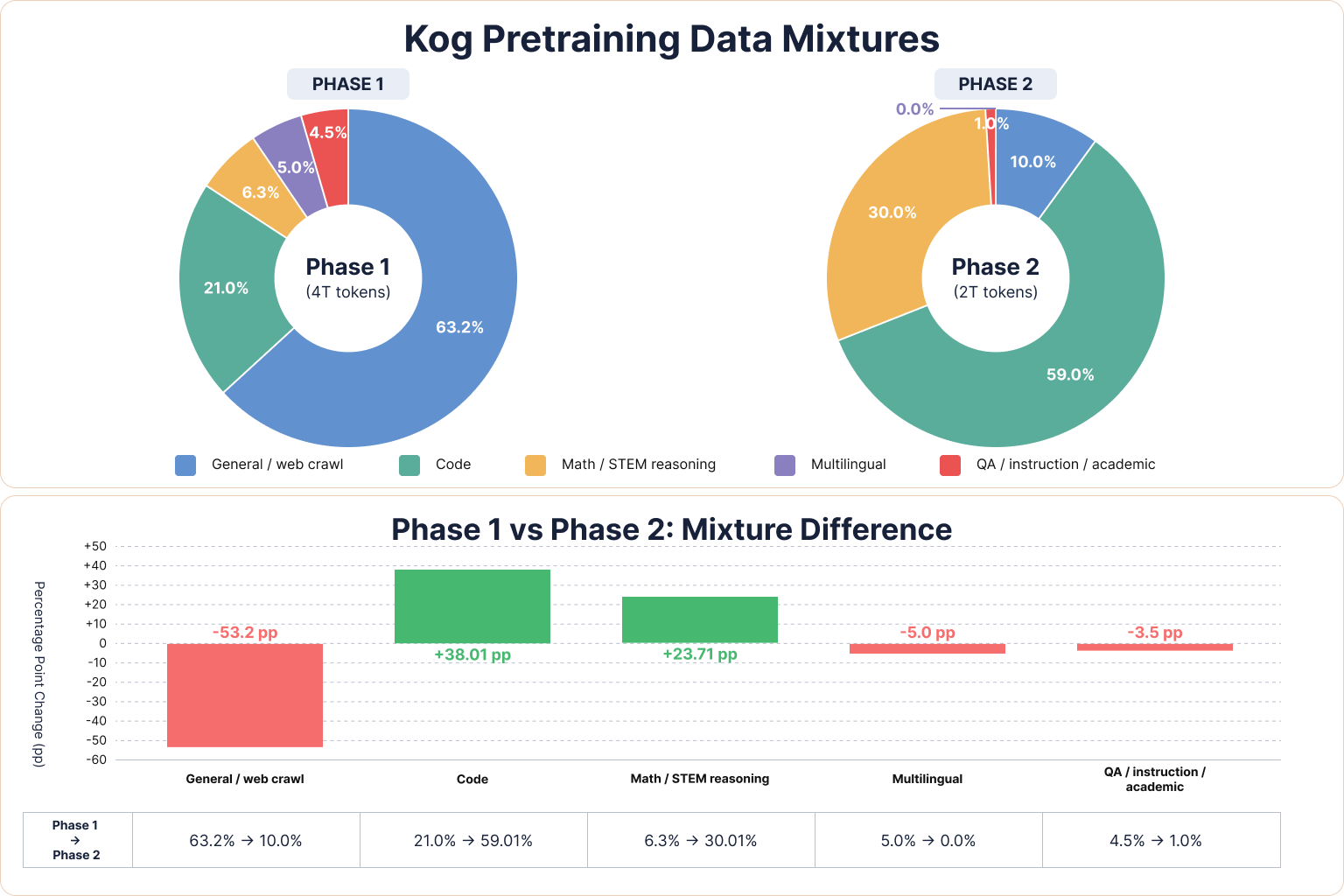
That being said, our 2B model is deliberately small. At this scale, it cannot absorb every useful signal contained in trillions of available tokens. So even if we could draw inspiration from Nemotron data mixtures, the final mixture had to be more selective. For Laneformer 2B, we introduced one twist: we concentrated most of the specialization in the second phase.
Phase 1 would build a broad base. Phase 2 would shift the model strongly toward coding and reasoning capability.
🤔 Remark
This was an explicit trade-off. But a strong data-mixture shift between phases is not standard practice, and we expected it to hurt some general capabilities. For this release, we accepted that risk, betting that we would receive in exchange a strong coding-focused model.
Infrastructure and performance
The training stack was built around repeatability as much as raw throughput: launch scripts with isolated snapshots, checkpoint conversion, HF export, validation, lm-eval support, CORE tracking, and dashboarding all became part of the project to ensure a reliable pre-training run with real-time monitoring.
No need to repeat how scary it is to spend hundreds of thousands of dollars on a run with no possibility of fixing it afterward. To avoid any potential training downtime we ensured with our partners that we could swap nodes effectively thanks to spare machines, and made restart reliability part of the training system.
We also spent quite a lot of time precisely tuning our model parameter budget, architecture details, number of data shards, and TorchTitan's distributed-training and compilation knobs to reach about 17k tokens/s/GPU during pre-training.
Our pre-training setup ended up being:
- 24 nodes with 8 NVIDIA H100 GPUs each, for 192 H100 GPUs.
- Efficient European infrastructure through Scaleway and ADASTRA.
- About 21 days of training.
- Mixed FP32/BF16 precision.
- Fully Sharded Data Parallel (FSDP) parallelism.
- AdamW with a WSD learning-rate schedule.
- Final-step checkpoint selection.
Runs
For pre-training and mid-training, we used TorchTitan as our distributed training stack. TorchTitan gave us a simple and reliable foundation for large-scale FSDP training while still leaving enough flexibility to support the custom Laneformer architecture.
Laneformer is close to a standard decoder-only Transformer in many ways, but its lane structure and DTP-oriented layout meant that we needed to control the model implementation, distributed configuration and compilation carefully.
The pre-training phases used a sequence length of 4,096 and a global batch size of 1,536, or about 6.29M tokens per optimizer step.
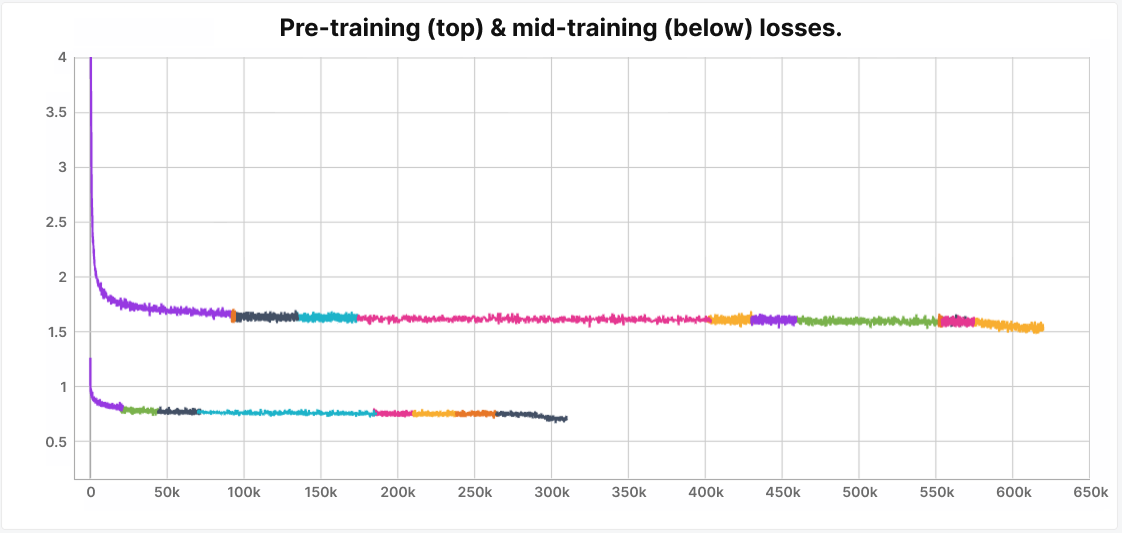
As we can see, moving to phase 2 drastically reduces the token diversity and the model stabilizes at a much lower cross-entropy than during phase 1. This is to be expected.
🤔 Remark
Although the chart shows multiple colors, they all correspond to the same training loss run. The color changes mark points where the training job was restarted from a temporary checkpoint after a failure.
Evaluation tracking
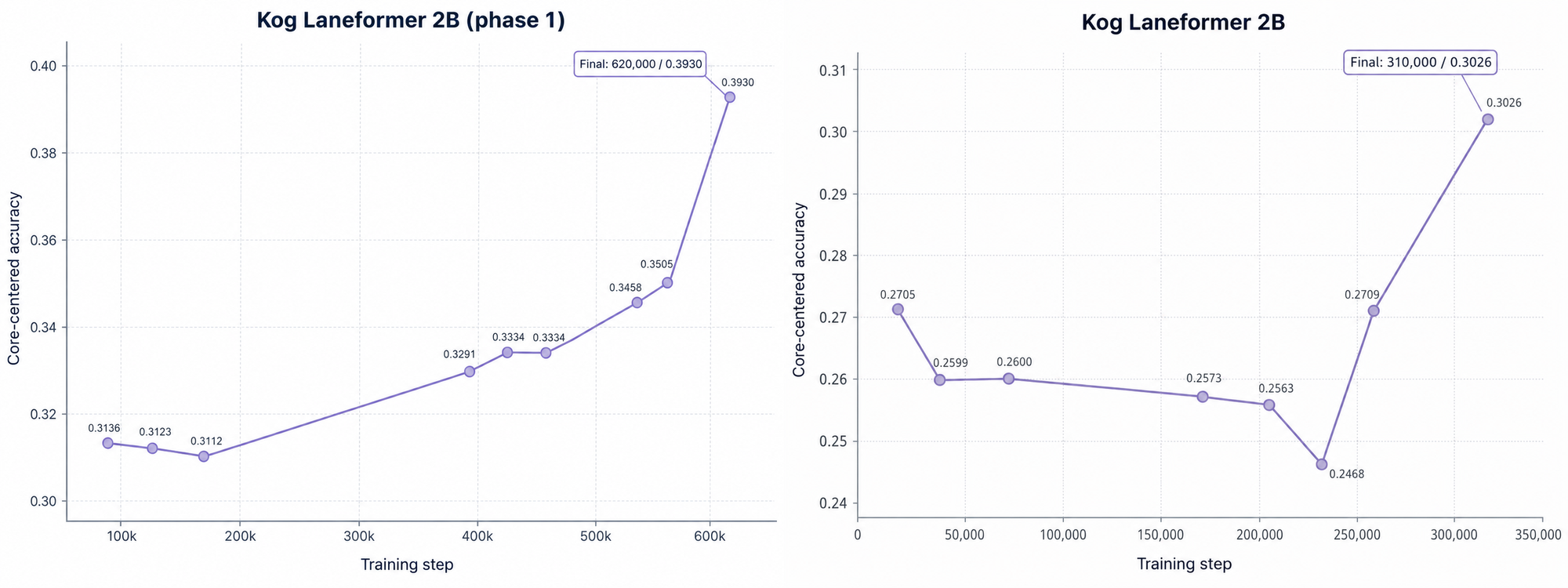
For the pre-training validation monitoring, we decided to use the DataComp-LM Core centered accuracy which is computed over 22 low-variance tasks by subtracting each task random baseline.
Besides the stable training loss curves (no spikes, no waves), this broad evaluation suite gave us the signal to ensure that our model was learning and improving across the whole training run.
Below, we can see the evolution of the metric across the two phases, we note an acceleration of performance during the learning-rate cooldown.
We also note that our choice to radically change the Phase 2 data mixture to coding/reasoning focused comes with a non-negligible cost on general capabilities of the model (We will see later, after post-training, that it was an acceptable price to pay).
Post-training
For post-training, we settled on a very simple recipe, focusing on Supervised Fine Tuning (SFT) with instruction and identity fine-tuning. Stay tuned for our next version of the model with a much stronger post-training pipeline.
Our goal was mainly to surface the base model's capabilities with a lightweight process, using around 200M tokens.
Notably, we experimented with synthetic data generation for the identity fine-tuning and saw promising possibilities for future releases!
Full training summary
| Stage | Tokens | Steps | Purpose |
|---|---|---|---|
| Pre-training | About 4T | 620,000 | Build the base model on broad Nemotron pre-training data |
| Mid-training | About 2T | 310,000 | Continue on a more code- and reasoning-heavy mixture |
| Post-training | About 210M | 200 | Instruction-tune the released model |
Evaluation
We evaluated our final instruct model on HumanEval+ and MBPP+ thanks to the official evalplus runner.
Even though evalplus already provides a preprocessing step to ensure the correct piece of code is evaluated, we added one more step to make sure that only the relevant code block is preprocessed when possible. This drastically improves the score of models that have a tendency to produce multiple code blocks per response, reducing variance when using pass@N settings.
🤔 Remark
This preprocessing step consists of making sure we select, if possible, only the "code block containing the target function name"; this is what we call target_function.
Here is a summary of our evaluation system, all models were evaluated with the exact same settings.
| Mode | greedy (temperature=0, do_sample=False) |
| Preprocessing | target_function block selection |
| Runner | evalplus |
Second phase validation
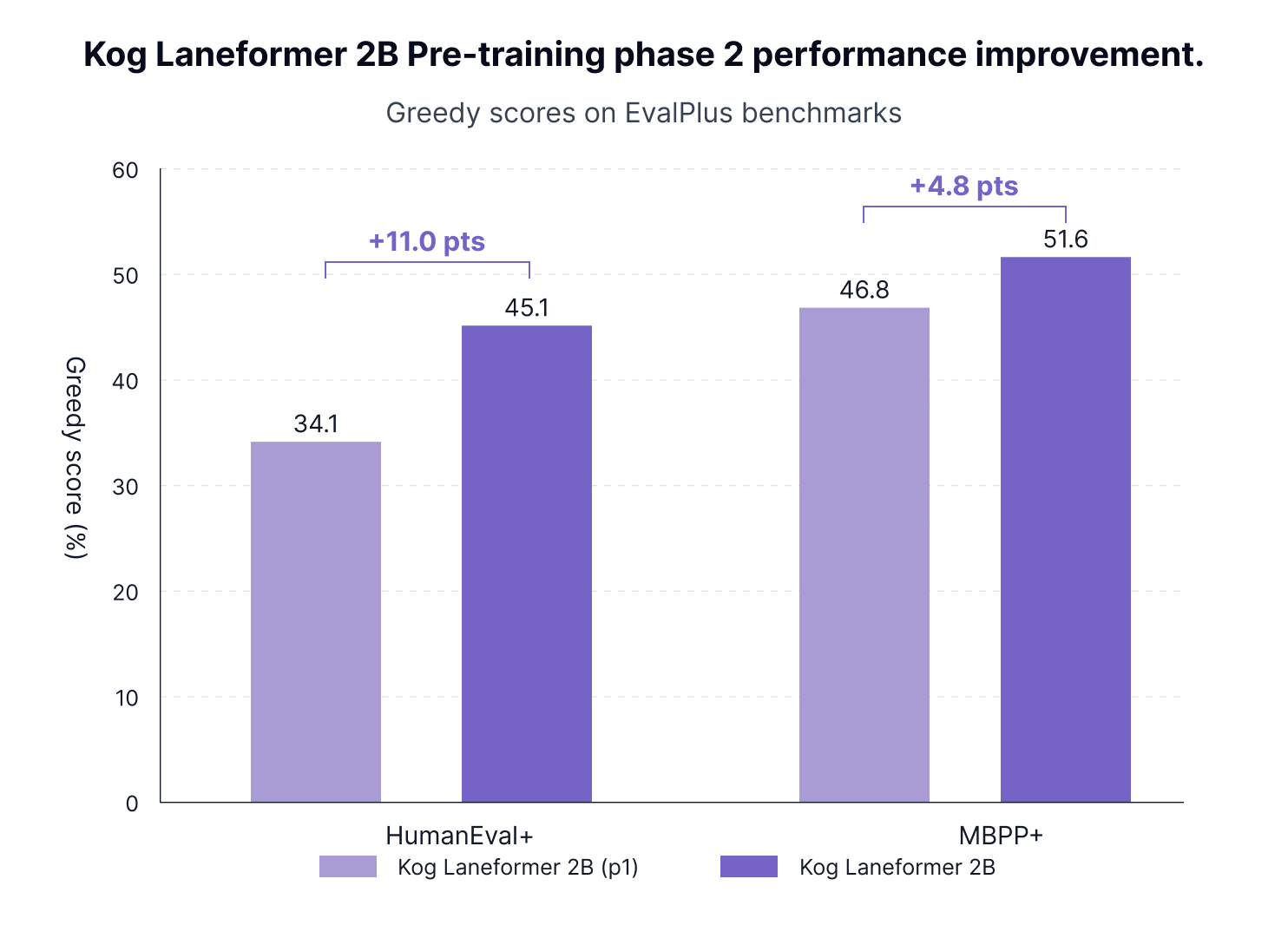
The first verification we ran on top of the base model CORE metrics is the MBPP+ and HumanEval+ benchmarks on our Phase 1 and Phase 2 base models post-trained for coding and instruction.
We find that:
- Phase 2 did improve our model's coding performance by more than 10 points across HumanEval+ tests.
Comparison with similar-size models
Finally, using our evalplus setup, we evaluate well-known public models in our size range to ensure that our training recipe is efficient.
We find that:
- Our model is extremely competitive for a model of its size on the different HumanEval benchmarks.
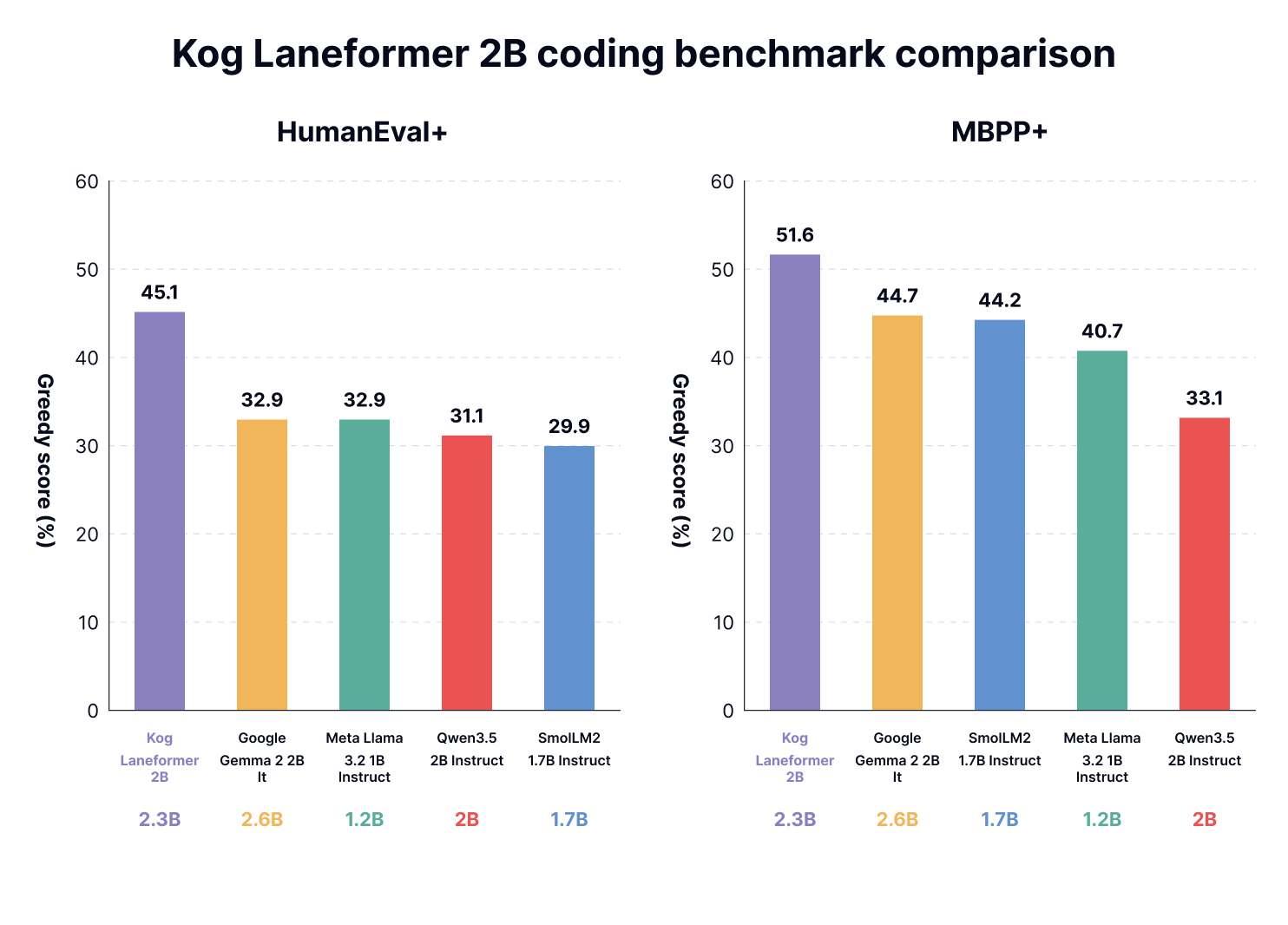
These results validate that the model is useful enough for small code-generation problems.
🤔 Remark
Laneformer benefits from stochastic decoding: pass@N improves consistently for N ∈ {2, 4, 8, 16}. As a single pass usually takes less than 0.3 seconds, sampling multiple candidate solutions becomes a practical way to trade a small amount of latency for higher coding accuracy.
Inference speed
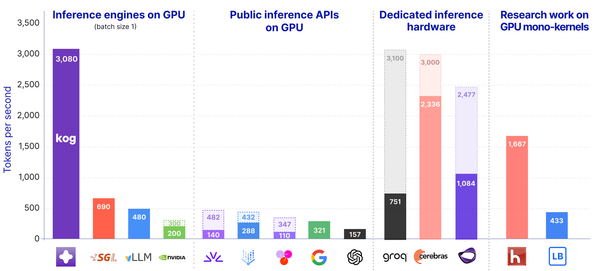
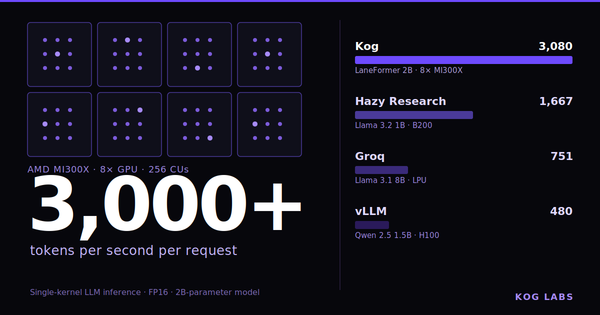
In our public KIE preview, Laneformer 2B reaches 3,000 output tokens/s/request on 8× AMD MI300X and 2,100 output tokens/s/request on 8× NVIDIA H200, using FP16, batch size 1, and no speculative decoding.
To our knowledge, this is the fastest publicly demonstrated single-request decoding results for a 2B-class model on standard datacenter GPUs.
Why open-source our 2B model?
This Hugging Face release lets you try the model as a Transformers-compatible model, read the custom architecture, run your own experiments, fine-tune it, or use it as a reference when thinking about latency-oriented model design.
It is both a usable checkpoint and a research artifact.
We believe open source is the best way to make this kind of systems and architecture work useful, inspectable, and extensible by the broader community.
We are sharing the weights, implementation, and recipe because we believe latency should be treated as a model design constraint, not only as a serving concern.
What we are releasing
kogai/laneformer‑2b‑it includes:
- An instruction-tuned Laneformer 2B checkpoint in BF16.
- A custom Hugging Face implementation for the
laneformerarchitecture. - Model configuration, architecture metadata, tokenizer information, and chat template.
- Evaluation results and documentation.
Kog-owned materials in the repository, i.e. model weights, custom Hugging Face code, configuration, metadata, documentation, and model card are released under Apache License 2.0. Tokenizer artifacts are based on the Llama 2 tokenizer and are distributed under the Llama 2 Community License; users and redistributors are responsible for complying with those terms.
To use it properly, please refer to the Hugging Face repository model card.
Limitations
Laneformer 2B is a small coding-focused model, not a general-purpose frontier model.
- Its 4,096-token context length and sliding-window attention choices reflect our latency target. Long-context extension is currently in progress.
- Our Phase 2 data mixture intentionally emphasizes code and reasoning, and CORE tracking suggests that this specialization comes at some cost to broad general capabilities.
- The released Hugging Face checkpoint is useful as a standard model, but the main latency benefits require the Kog Inference Engine and the DTP-aware execution path.
Conclusion
We are releasing Laneformer 2B, a small language model with coding capabilities. In addition to the final instruct model checkpoint, we also share the full backstory and training recipe, including pre-training, mid-training, post-training, and evaluation details.
We hope this model will spark interest in a new kind of model architecture, co-designed with hardware in mind, not only to achieve high benchmark performance but also to reach high TPS at inference time!
Acknowledgments
Laneformer 2B was trained and released with support from several partners and open ecosystems. We thank Scaleway and Adastra for the French GPU infrastructure used during training, the TorchTitan project for the distributed training foundation, Hugging Face for the release platform and Transformers ecosystem, NVIDIA for the Nemotron datasets and papers, and evalplus for their rigorous evaluation framework!
A special shout-out to the global machine-learning community and open-source ecosystem, without which this work would never have been possible.
Explore these links to dig deeper
- Test our speed in the Kog Playground
- Kog Laneformer 2B HF model: huggingface.co/kogai/laneformer‑2b‑it
- Kog Inference Engine launch post: blog.kog.ai
- Kog monokernel post: blog.kog.ai
- Delayed Tensor Parallelism post: blog.kog.ai
- Nemotron dataset: huggingface.co/collections/nvidia/nemotron
- Hugging Face Smol training playbook: Smol training playbook
Citation
If you use Laneformer 2B, please cite this blog post:
@online{kog_laneformer_2b_2026,
title = {{Laneformer 2B: The Latency-First Model Behind Kog Inference Engine}},
author = {Kog Team},
year = {2026},
url = {https://blog.kog.ai/kog-laneformer-2b-the-latency-first-model-behind-kog-inference-engine},
note = {Kog blog}
}