Today Kog is releasing the weights and model code of Laneformer 2B on Hugging Face Hub, the 2.3B-parameter instruction-tuned coding model designed for high-speed decoding.
Most LLM research optimizes for benchmark quality first, and inference metrics like speed are often treated as a serving problem that
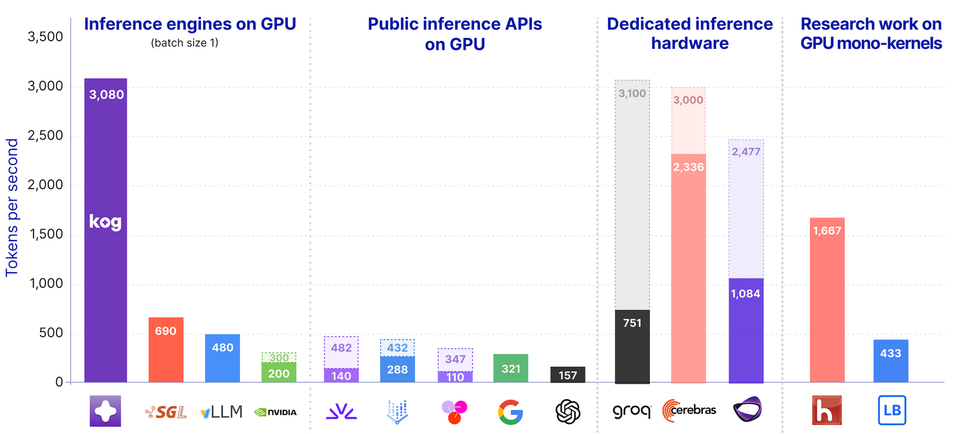
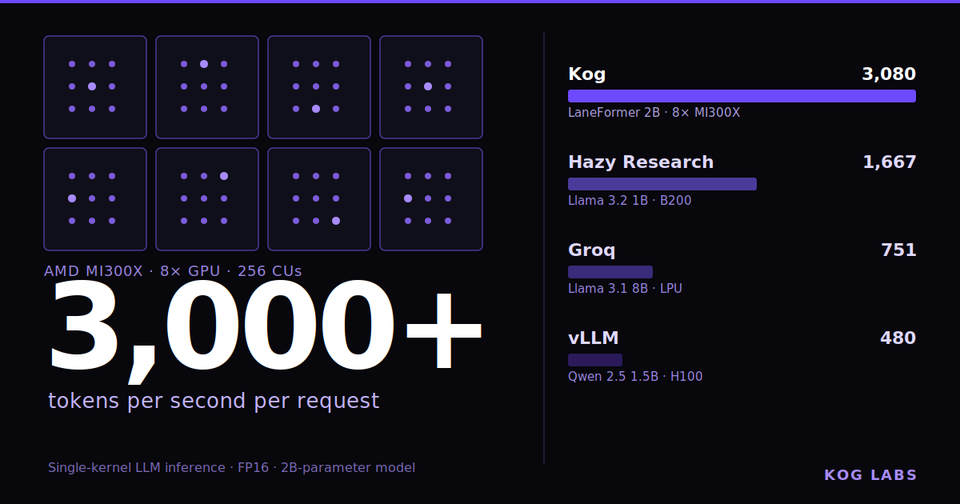
Today, Kog AI launches a tech preview of the Kog Inference Engine (KIE): 3,000 output tokens/s per request on 8× AMD MI300X GPUs and 2,100 on 8× NVIDIA H200 (FP16, no speculative decoding). This preview runs a 2B model, with support for large third-party MoE models coming next at similar speeds.
We implemented the entire LLM decode pass in a single persistent kernel, no kernel launches, no interruptions, achieving 3,000+ tokens/s per request on AMD MI300X.
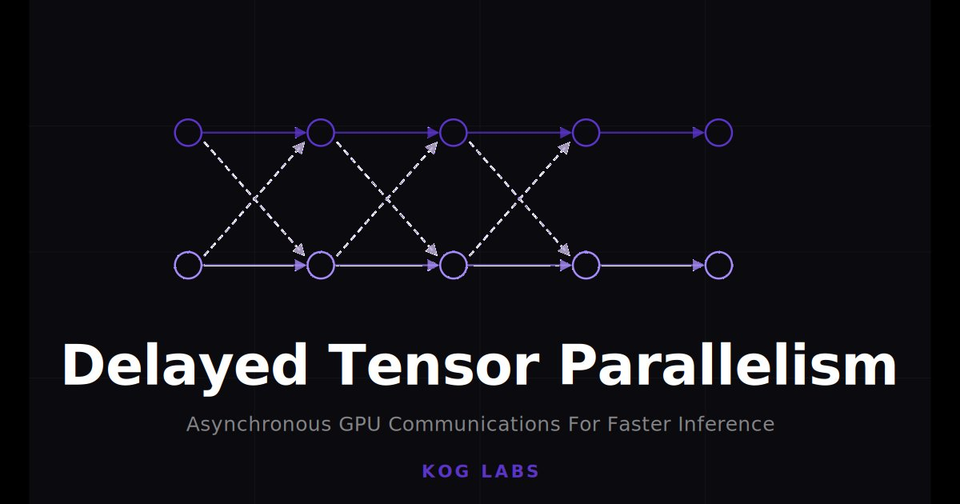
DTP is a new Transformer architecture that hides communication overhead behind computation and weight streaming, enabling significantly faster batch-size-one inference on AMD and NVIDIA GPUs.