Inference
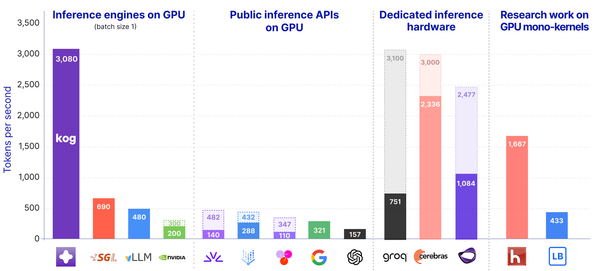
Real-time LLM Inference on Standard Datacenter GPUs (3,000 tokens/s per request)
Today, Kog AI launches a tech preview of the Kog Inference Engine (KIE): 3,000 output tokens/s per request on 8× AMD MI300X GPUs and 2,100 on 8× NVIDIA H200 (FP16, no speculative decoding). This preview runs a 2B model, with support for large third-party MoE models coming next at similar speeds.
