GPU Engineering
Building a single-kernel, latency-optimized LLM inference engine on AMD MI300X GPUs
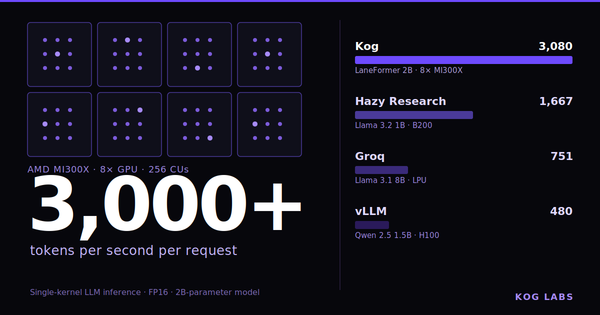
We implemented the entire LLM decode pass in a single persistent kernel, no kernel launches, no interruptions, achieving 3,000+ tokens/s per request on AMD MI300X.
